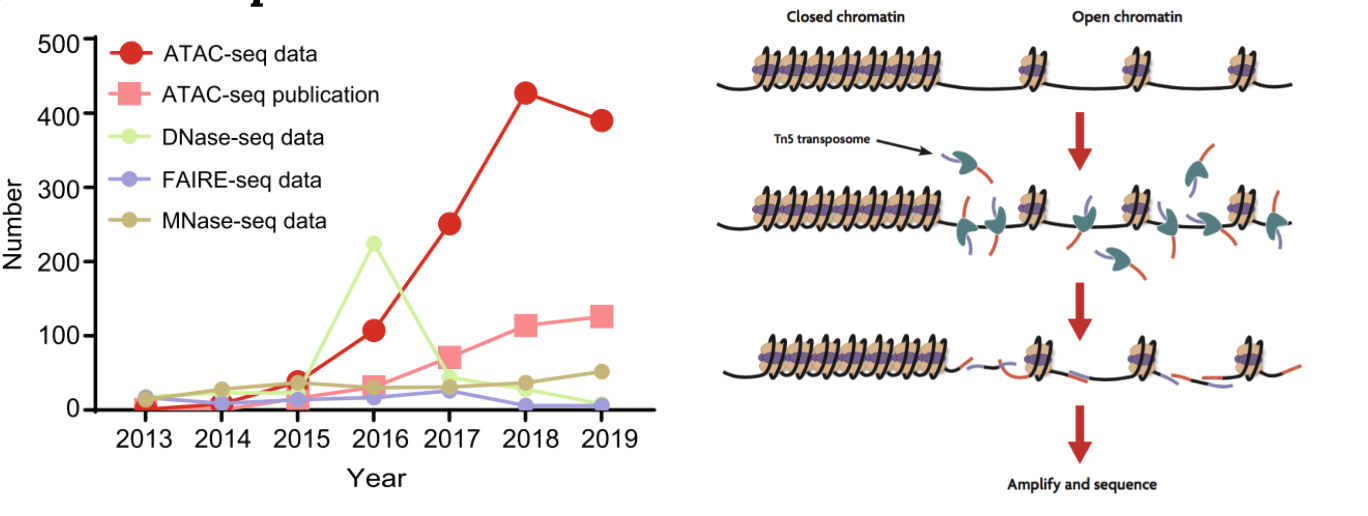
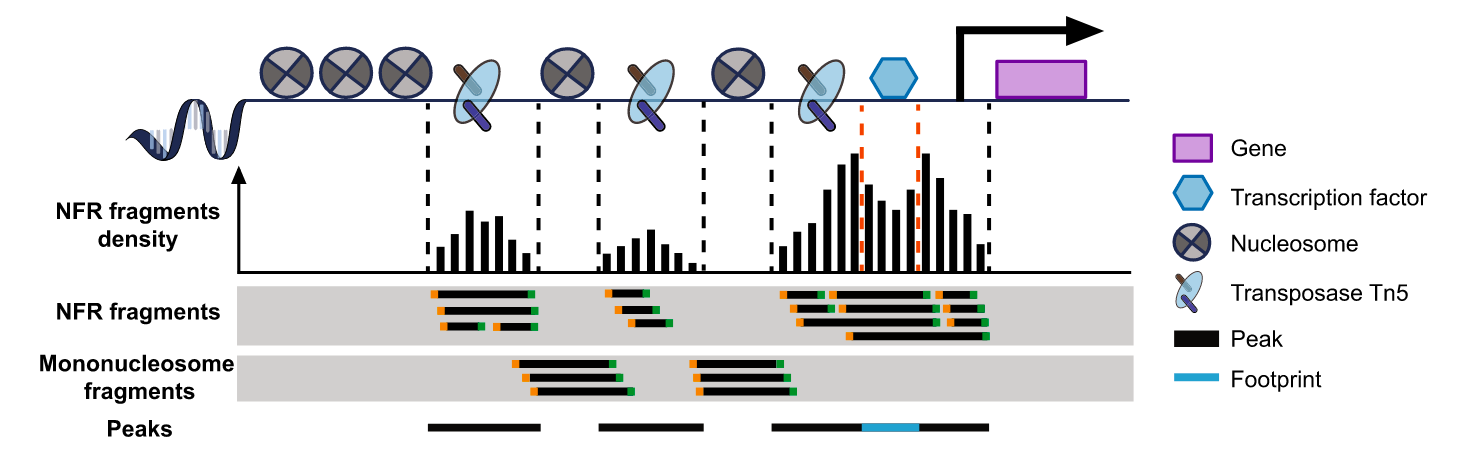
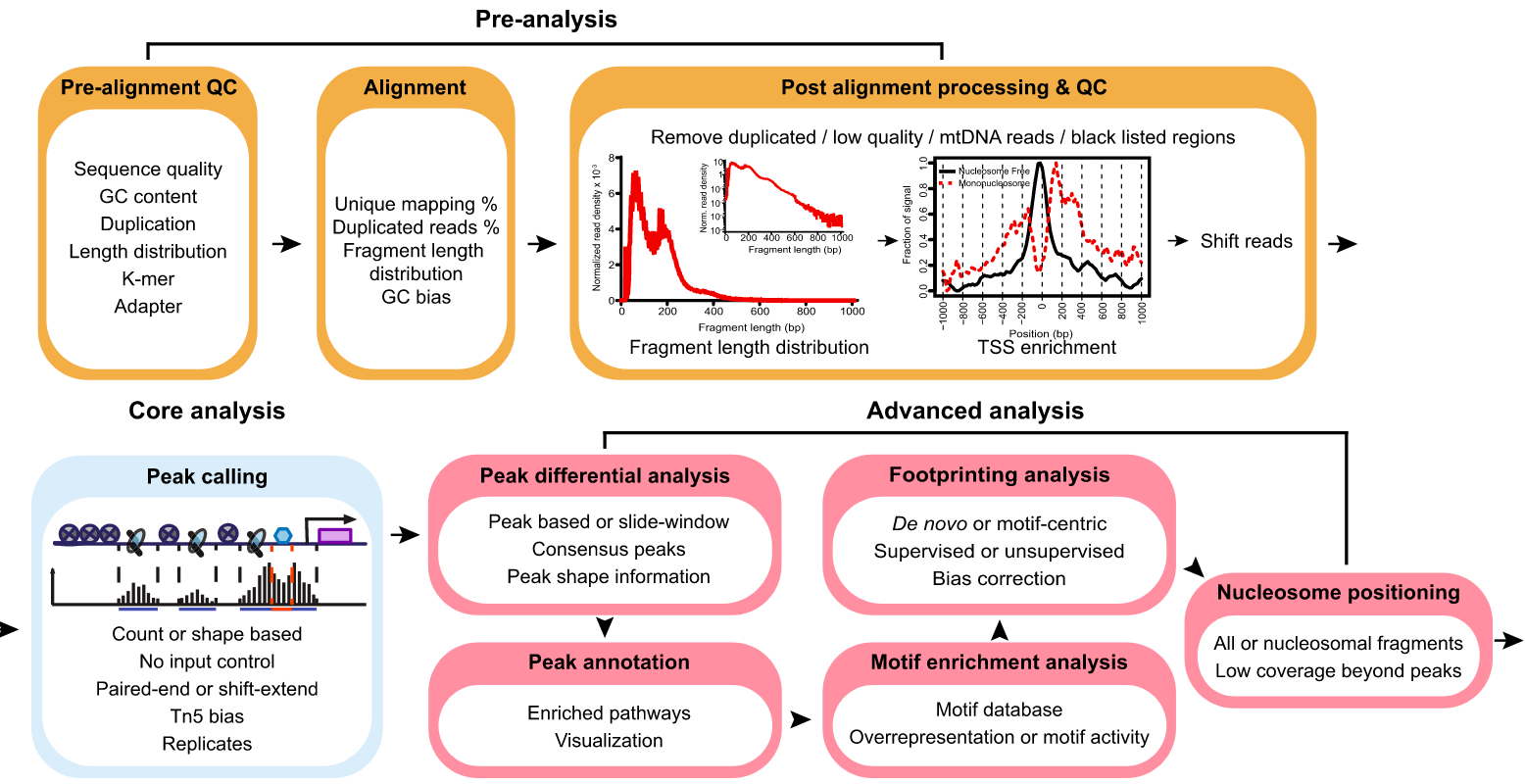
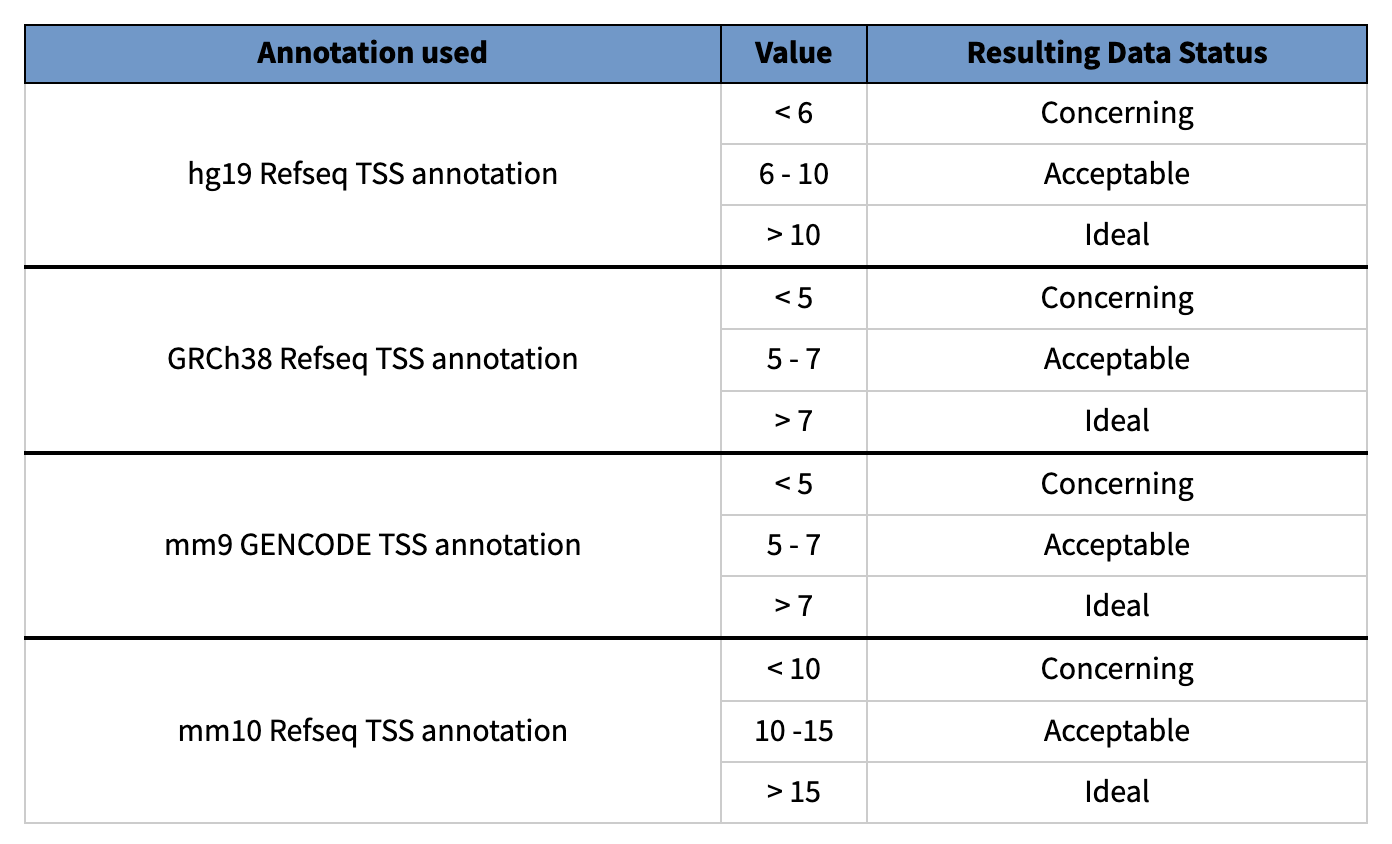
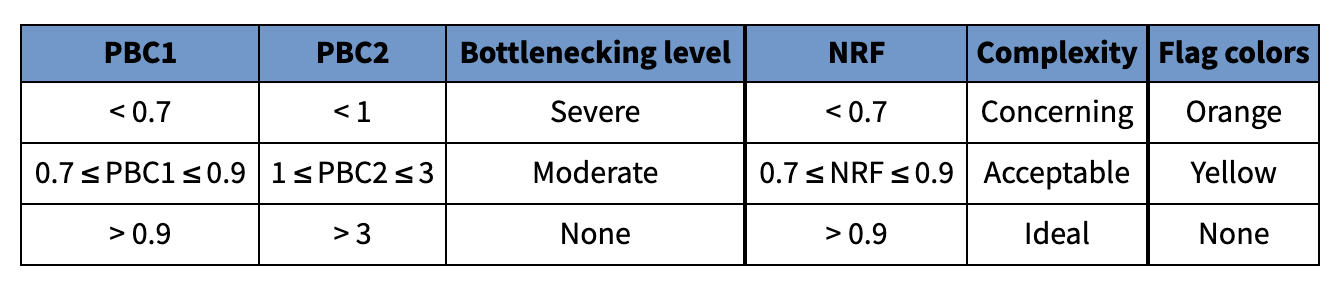
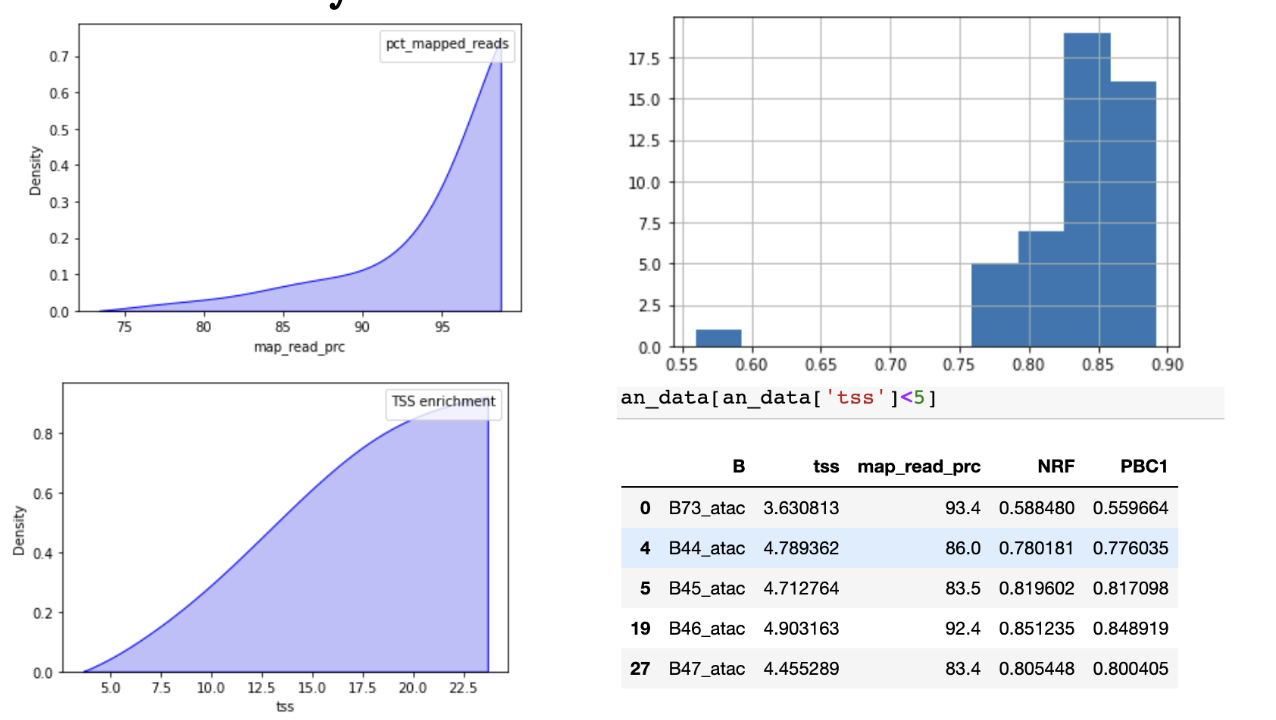
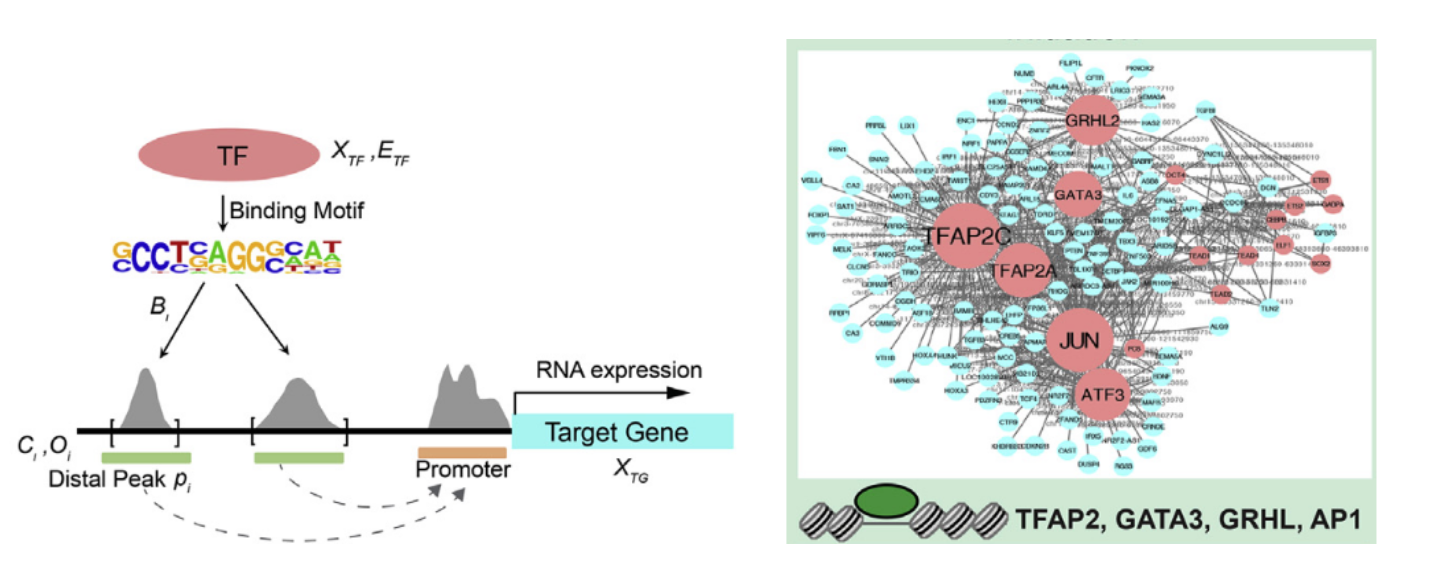
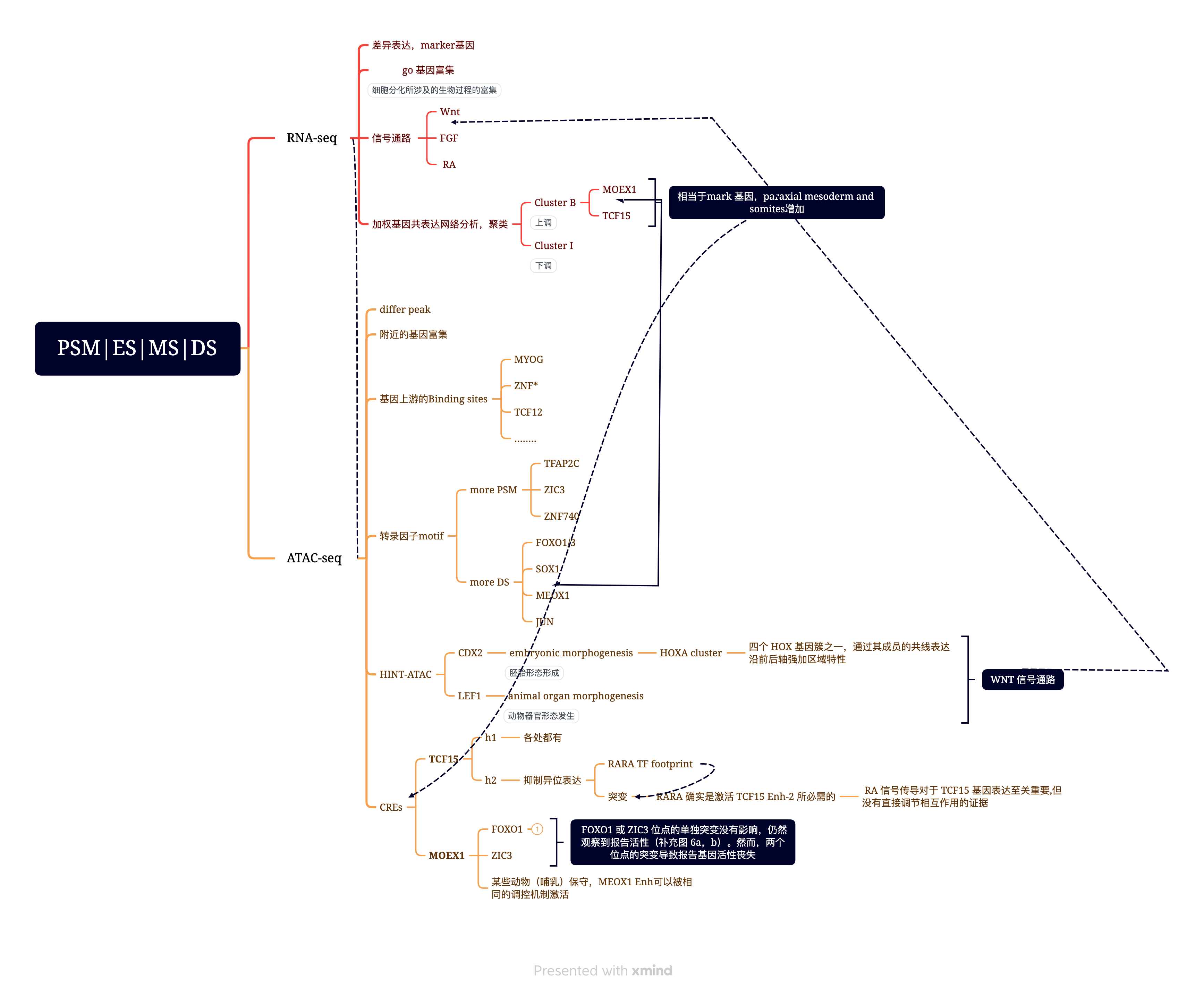
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| base <- read.table("/media/wvdon/sdata/atac-seq/before/all_new_feature.txt",row.names = 1 ,header=T,sep = '\t')
basedata=base[6:ncol(base)]
group_list <- factor(c(rep("IM",8), rep("NC",8)))
table(group_list)
colData <- data.frame(row.names=colnames(basedata),group_list=group_list)
head(basedata)
colnames(colData)
ncol(basedata)
nrow(colData)
library(DESeq2)
dds <- DESeqDataSetFromMatrix(countData = basedata,colData = colData,
design = ~ group_list)
dds_2 <- DESeq(dds)
resultsNames(dds_2)
res <- results(dds_2)
diff_gene_deseq2 <-subset(res, padj < 0.05 )
up_DEG <- subset(res, padj < 0.05 & log2FoldChange > 1)
down_DEG <- subset(res, padj < 0.05 & log2FoldChange < -1)
dim(up_DEG)
dim(down_DEG)
library(biomaRt)
human <- useMart('ensembl',dataset = "hsapiens_gene_ensembl")
gene_id = row.names(diff_gene_deseq2)
gene_name<-getBM(attributes=c("ensembl_gene_id","external_gene_name"),filters = "ensembl_gene_id",values =gene_id , mart = human)
library(ggplot2)
library(ggrepel)
library(pheatmap)
row.names(assay(dds_2))
head(assay(dds_2))
rownames(gene_name)=gene_name$ensembl_gene_id
final_rna =merge(gene_name,assay(dds_2), by = "row.names",all=F)
dim(assay(dds_2))
head(final_rna)
heat_map_data=final_rna[4:ncol(final_rna)]
dim(heat_map_data)
Groups=c(rep("IM",8),rep("NC",8))
annotation_c<-data.frame(Groups)
annotation_c<-data.frame(Groups)
rownames(annotation_c)<-colnames(heat_map_data)
data<-log2(heat_map_data+1)
colnames(data)
ac = c("37AC73","30A72","33A37","46A94","47A84","49AC90","13A87","54A80",
"37C74","30C78","33C82","46C81","47C79","49C93","13C64","54C62")
p<-pheatmap(data, cluster_rows = T,
cluster_cols = F,
show_rownames = F,
show_colnames = T,
annotation_col = annotation_c,
scale = "row",
labels_col= ac,
angle_col = 30,
border=F
,color = colorRampPalette(colors= c("blue","white","red"))(10)
)
p
ggsave(file="/media/wvdon/sdata/atac-seq/before/heatmap_rna.svg", plot=p, width=8, height=8)
final_rna_vo =merge(gene_name,DataFrame(diff_gene_deseq2), by = "row.names",all=F)
write.csv(final_rna_vo,'/media/wvdon/sdata/atac-seq/before/vo.csv')
data<-read.csv('/media/wvdon/sdata/atac-seq/before/vo.csv')
data$log2FoldChange=-data$log2FoldChange
cut_off_pvalue=0.05
data$external_gene_name
PvalueLimit = 5
data$label=ifelse(-log10(data$pvalue) > PvalueLimit , as.character(data$external_gene_name), '')
data$group<-as.factor(ifelse(data$pvalue <= 0.05 & abs(data$log2FoldChange) >=0,
ifelse(data$log2FoldChange<=0 ,'down','up'),'NS'))
this_tile <- paste0('Cutoff for logFC is abs 1.0 and pvalue is 0.05',
'\nThe number of up gene is 59',
'\nThe number of down gene is 43')
p <- ggplot(
data,
aes(x = log2FoldChange,
y = -log10(pvalue),
colour=group)) +
geom_point(alpha=0.4, size=3.5) +
ggtitle( this_tile ) +
geom_vline(xintercept=c(-1,1),lty=4,col="black",lwd=0.8) +
geom_hline(yintercept = -log10(cut_off_pvalue),lty=4,col="black",lwd=0.8) +
labs(x="log2(fold change)",
y="-log10 (p-value)")+scale_color_manual(values = c( 'green','red'))+
theme_bw()+
geom_text_repel(aes(x = log2FoldChange,
y = -1*log10(pvalue),
label=label),
max.overlaps = 10000,
size=5,
box.padding=unit(0.5,'lines'),
point.padding=unit(0.1, 'lines'),
segment.color='black',
show.legend=FALSE)
p
ggsave(file="/media/wvdon/sdata/atac-seq/before/vo_rna.svg", plot=p, width=8, height=8)
write.csv(data,'/media/wvdon/sdata/atac-seq/before/p005_filter_rna_before.csv')
human <- useMart('ensembl',dataset = "hsapiens_gene_ensembl")
gene_id = row.names(res)
gene_name<-getBM(attributes=c("ensembl_gene_id","external_gene_name"),filters = "ensembl_gene_id",values =gene_id , mart = human)
res$log2FoldChange=-res$log2FoldChange
rownames(gene_name)=gene_name$ensembl_gene_id
all_before_rna = merge(gene_name,DataFrame(res), by = "row.names",all=F)
write.csv(all_before_rna,'/media/wvdon/sdata/atac-seq/before/all_before_rna.csv')
|